Today we'd like to announce the open-sourcing of Remainder (Reasonable Machine Learning Doubly Efficient Prover), Tools for Humanity's in-house GKR + Hyrax proof system. Remainder enables World’s users to run ML models locally over private data and prove that they executed them correctly, allowing powerful use-cases like on-device iris code upgrade from images without re-visiting an Orb. The open-source codebase is available here along with the companion Remainder Book (highly recommended!) here.
Introduction
This blog covers the design decisions that went into building Remainder. To make it compatible with different GKR ideologies, Remainder includes several features that differ from typical GKR implementations:
- A claim-centric view of GKR that treats it as a general claim reduction and aggregation framework, allowing support for:
- "Structured" layers, allowing for linear-time verification for a type of computation that most machine-learning algorithms fall under.
- "Gate" layers, encompassing other arithmetic computation that might not be structured.
- Dataparallel layers, which allow us to efficiently verify many executions of the same circuit.
- Configurable claim aggregation strategies that trade off prover/verifier runtime and memory in explicit ways.
- Accessible circuit frontend you can use to build your own circuits!
If you've been intending to dive into how GKR works in practice, this blog is for you! We'll be discussing the algorithmic ideas that make Remainder both surprisingly powerful and expressive for real-world ZKML.
Background
ZK proofs on the edge are critical for doing two things simultaneously: maintaining user data privacy (by keeping data strictly on users' mobile devices) while ensuring that users cannot cheat the system by running anything but the correct program.
Our goal is to constantly improve the IrisCode pipeline/algorithm, yet upgrading existing users’ IrisCodes in a secure, privacy-preserving manner is no easy feat. Broadly, there are three possible approaches:
- Server-side re-processing: One option—typically chosen by legacy providers—is to have users upload their iris images to our cloud and run our new IrisCode model there. While this approach maintains correctness, it would require users to send images of themselves to our servers.
- Unverified client-side execution: Another option is to send the latest IrisCode model to every user’s mobile device and have them run the model on their iris images locally. While this approach maintains privacy, there is no way to guarantee that users are running the correct model to upgrade their IrisCodes.
- Verified client-side execution with ZK proofs: The third option is for us to send users the latest IrisCode model and have them run that model locally. However, rather than just blindly trusting the user's claimed result, we ask the user to also provide a proof , which shows that the correct model was run on an attested input (i.e., an iris image which actually came from an Orb) to produce exactly the result that the user sent. This approach maintains both privacy and correctness at the cost of runtime/RAM.
The primary challenge here is thus performance—mobile devices are compute- and RAM-limited, and we want to make this proving capability accessible to as many devices as possible. Given this constraint, we choose to implement a prover that is specialized to our particular application: the IrisCode algorithm.
More details can be found in this blog, but at a high level, the IrisCode algorithm is highly structured and layered. In other words, this algorithm can be divided into clear steps (encoded as layers of a circuit), where the output of each step is the input of the next, and almost every step can be encoded as a function whose output label is directly computable from its input label. We wish to take advantage of these two properties of the IrisCode algorithm within Remainder—hence, we use the GKR proof system with several algorithmic optimizations and a zero-knowledge wrapper over GKR proofs via the Hyrax interactive protocol.
Remainder Features!
Typically, GKR is associated with two different styles of layerwise computation.
The more common style of GKR computation in literature is to use gates—where we define output of a computation using binary gates that dictate how to combine values in a previous computation. For example, if we want to add every other pair of values in a layer and multiply the remaining pairs of values in that same layer to result in the output of the next layer, we could define this computation using and binary gates:
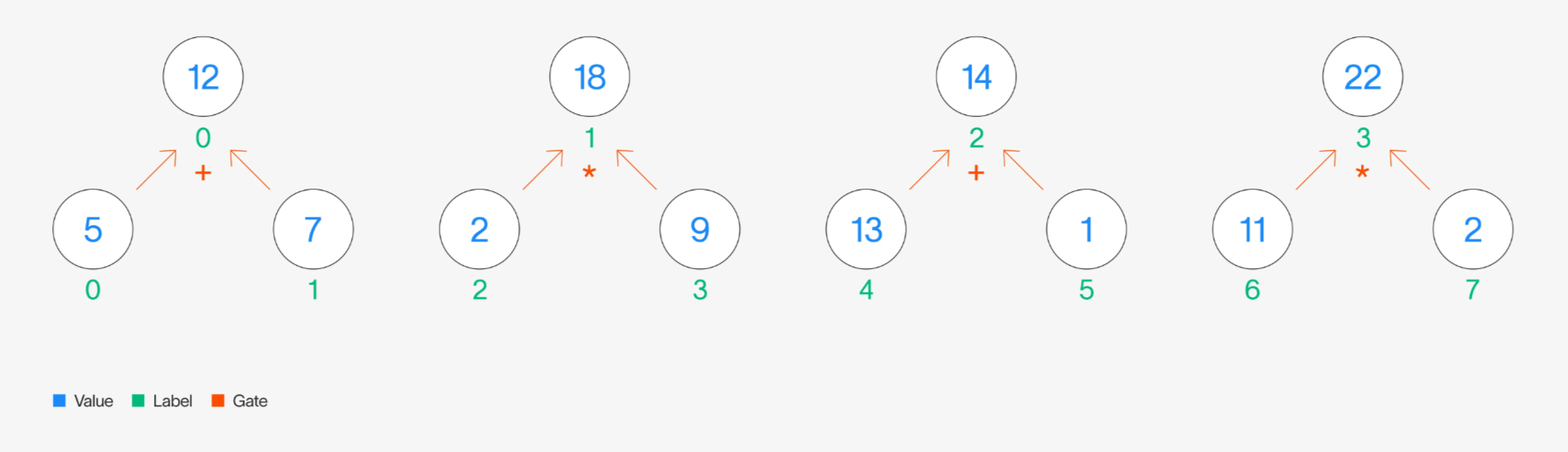 Gate-style layer computation example
Gate-style layer computation example
Let be a function over the labels of the nodes in the bottom layer, outputting the value of each node. For example, and . Similarly, define to be a function over the top layer.
Then, one way to represent in terms of is to say:
Another style of GKR takes advantage of the structure of layers. At a high level, this is when we can notice a pattern for which nodes in the previous layer are combined to produce the values of the next layer. For example, in the diagram above, there is a clear pattern: we take every other pair of nodes and aggregate their values using a binary or gate.
Alternatively, rather than spelling out each gate in the circuit and its location, we can represent in terms of in a simpler manner:
We refer to this style of expressing layerwise relationships in GKR as "structured GKR."
GKR as a General "Claim-Reduction" Framework
Although GKR is usually compartmentalized into one of these frameworks (gate or structured), we choose to look at GKR differently—as a claim-reduction framework. Remainder takes any type of multilinear extension (MLE) relationship which is provable via a claim-reduction strategy of some kind (currently, this is almost exclusively sumcheck) and fits it into its claim-reduction + aggregation framework.
The key idea here is that, rather than viewing GKR as a strict protocol for evaluating layered circuits where the layerwise relationship can be expressed using indicator gate polynomials, Remainder views GKR as an abstract protocol with two primary (generally alternating) components: claim reduction and claim aggregation.
- A claim refers to an unproven MLE evaluation the prover wishes to show is true, e.g., (we should read this as "the verifier wishes to know whether the MLE evaluated at public evaluation points is indeed ").
- Claim reduction refers to the idea that one claim, e.g., from above, can have its validity reduced to that of another set of claims, e.g., , where the other set of claims is "closer" to something that is directly checkable by the verifier. (In this case, if the verifier has access to the evaluations of , then they can check the above claimed evaluations directly.)
- Claim aggregation refers to the idea that, given a set of claims over the same MLE, e.g., the above set , we can reduce the validity of all such claims on that MLE to that of a single claim, e.g., .
- We note that roughly playing the following game is precisely the more general version of the GKR framework Remainder implements:
- Start with circuit outputs or other direct claims the prover wishes to make.
- For all remaining sets of claims on MLEs, do the following:
- Aggregate the claims within the set on a single MLE to a single claim.
- Use the claim-reduction strategy for that MLE and add remaining claims to other sets.
- The idea of a layered circuit is still natively supported within Remainder, but the prover and verifier are both claim-centric rather than circuit-centric—any polynomial relationship expressible in Remainder's
Expressionfrontend can be proven via sumcheck, and claims are agnostically accounted for and thrown into their correct layered "buckets" rather than being hard-coded.
Claim Reduction Strategies/Layers
We briefly detail the style of polynomial relationships that Remainder implements. Each naturally defines one claim-reduction strategy, e.g., sumcheck over the polynomial on the RHS.
Linear-Time "Gate"-style Layers
See our documentation page here for more details.
Recall that for "gate"-style layers, the layerwise relationship can be expressed in the form
where is the multilinear extension of the indicator function representing whether the th wire value from the th layer and the th wire value from the th layer contribute (via the binary operator, which is typically or ) to the th wire value in the th layer for . Note that are the number of variables in the MLE representing the th and th layers, respectively.
A naive implementation of a sumcheck prover for the above would require looping through all of the in time and computing each summand term in . However, using a trick from [XZZ+19], Remainder’s prover is able to compute the above in time , which is linear in the size of the layers.
Linear-Time "Structured"-style Layers
See our documentation page here for more details.
"Structured" layerwise relationships follow from Theorem 1 of [Tha13] and describe a relationship between layer values where bits of the index of the "destination" value in the th layer are a(n optionally subset) permutation of the bits of the index of the "source" value in the th layer for . For example, a structured relationship that takes one "source" MLE and computes products of adjacent values within it to produce would be described as follows —
Note that the above RHS summand is cubic in , i.e., the variables to be sumchecked over. For layerwise relationships of constant degree where and are the number of variables representing the th and th layers, respectively, Remainder’s prover runs in , i.e., linear in the size of the layers.
When the IrisCode algorithm is expressed as an arithmetic circuit, similar to most machine learning computation, most of the circuit's layers are structured layers. By supporting linear-time proving of structured layers, we can take advantage of this fact.
Time-Optimal Matrix Multiplication
See our documentation page here for more details.
We have matrices resulting in such that is the matrix multiplication product of and :
We extend the above matrices into MLEs:
The equivalent matrix multiplication relationship from above is then
Remainder’s prover is able to prove this relationship for any in , which is identical to the time it takes the prover to simply read the contents of and , i.e., time-optimal. This allows us to reduce claims on to ones on and , as desired.
The IrisCode algorithm has a convolution, which can be represented as a matrix multiplication layer. By using this time-optimal algorithm, Remainder handles this layer in the most efficient way possible.
Dataparallelism
One advantage of GKR is its support for dataparallel computation. Oftentimes, we wish to execute the same circuit over many different inputs. If the cost of verifying the execution of a circuit is , then naively, the cost of verifying inputs over the same circuit is . However, with GKR and in Remainder, we have built-in support for dataparallelism, where the cost of verifying inputs over a circuit is .
For simplicity, let us consider a circuit with the single layer described in the "structured" layers section. Drawn out, the circuit would look like this:
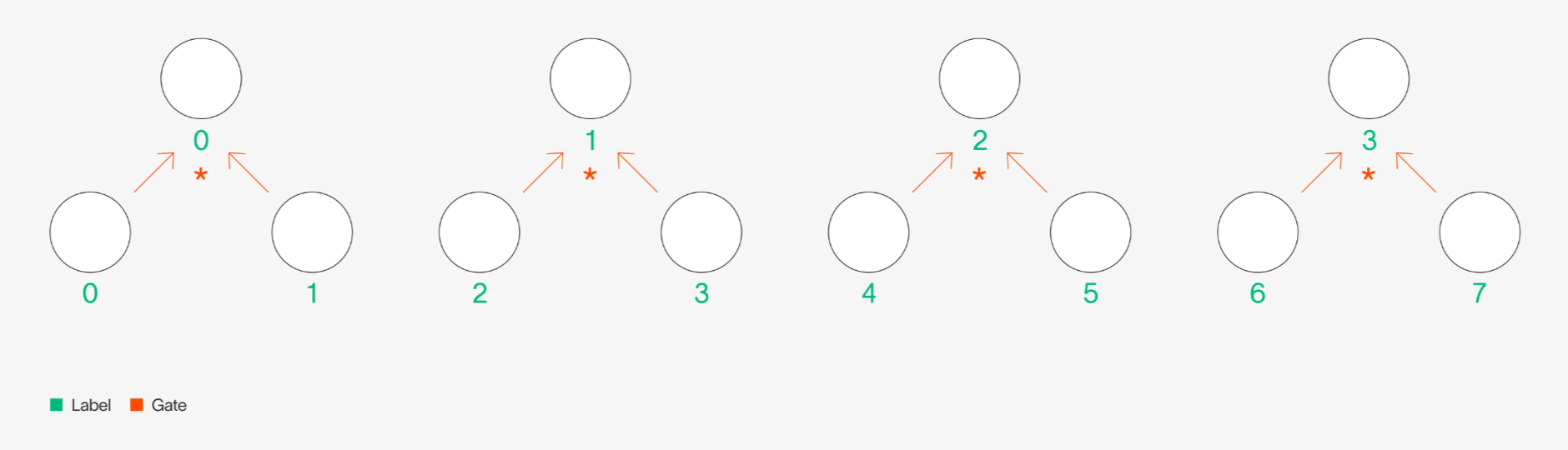 Structured layer circuit diagram
Structured layer circuit diagram
And the MLE relationship of this layer, as written earlier, is:
Note that the MLEs and have number of variables, because we express the label index in binary. There are eight values in the bottom layer whose pairwise product results in the next layer, and therefore has variables and has variables.
If we wanted to validate the execution of this circuit times, over different inputs, we could simply do separate sumcheck proofs for the equation above, over the four different inputs. Sumcheck is work for the verifier, so this would take in total time . However, because GKR is so amenable to layers that have structure, another way to see this is as a single circuit, but with just times the width. If , we would have the following:
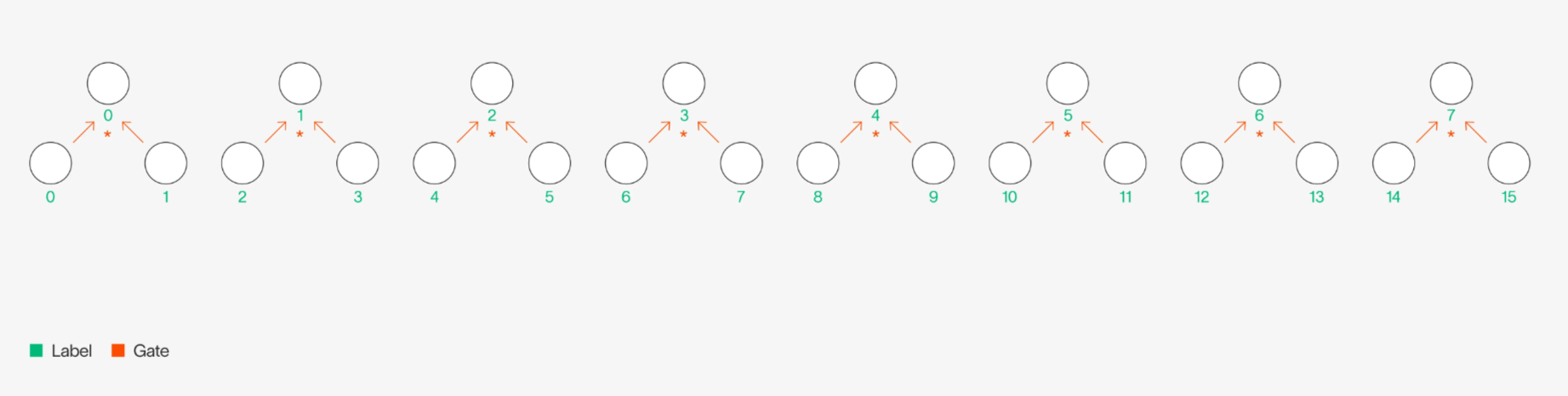 Dataparallel circuit with doubled width
Dataparallel circuit with doubled width
Then, the MLE relationship for this wider circuit would be as follows:
In fact, we can even think of the original layer as repeating the same (even smaller) circuit times, and the first two variables of the original as indexing into which “copy” of the circuit we are working with.
As opposed to above, the time it would take to verify this single sumcheck equation would be as opposed to . In other words, with dataparallelism, verification time increases by an additive logarithmic factor with the number of copies of the circuit we would like to verify, as opposed to the naive strategy, which would scale linearly.
A lot of compute in machine learning is performed in a dataparallel manner, making GKR’s natural support for dataparallel computation meaningful when applied to validating machine learning inference.
Claim Aggregation Algorithms
See our documentation page here for more details!
On one hand, we have strategies to reduce the validity of one layer to the validity of the layers it depends on. As explained earlier, this results in claims on one layer "propagating" to claims on another layer. For a concrete example of how this happens, without going into too much technical detail, we start with the following "gate" layer as described above:
To verify the claim on the value of , we run the sumcheck protocol between a prover and verifier. In the last round of sumcheck, the prover sends the value , which is purportedly the value:
To verify this, the verifier needs and , which are sent as claims from the prover:
And the verifier can verify these claims by performing sumcheck over another GKR layer. However, as we can see, one claim on the layer resulted in two claims on the layer . For a circuit which contains layers, this will result in a number of claims on the final layer proportional to . To avoid this blow-up, we engage in a protocol called "claim aggregation," which, in exchange for a negligible soundness hit, reduces the validity over claims to the validity of a single claim or a single sumcheck equation, depending on the strategy.
In Remainder, we allow circuit builders to configure which strategy of claim aggregation they would like to use, depending on which constraints they are optimizing for. We are able to do this because we view claim aggregation as a separate framework.
Interpolative Claim Aggregation
At a high level, interpolative claim aggregation works by taking claims on an MLE and fitting each of the claimed points to a line. In other words, if we have the following claims:
then both the prover and the verifier compute the following interpolating polynomial such that:
Then, the prover sends to the verifier the polynomial , or in other words, the restriction of to points generated by . The verifier then chooses a random point , where . The prover and verifier then engage in a single sumcheck to verify whether .
The majority of the cost here comes from the degree blow-up of , which is .
We have implemented several optimizations within Remainder to reduce the degree of this polynomial and therefore reduce the complexity of this method of claim aggregation. However, in some cases, we may still opt for a different type of claim aggregation, which comes with a different set of trade-offs.
Random Linear Combination (RLC) Claim Aggregation
RLC claim aggregation, contrary to the name, does not aggregate claims at all. Instead, it “folds” all of the claims into a single sumcheck equation. For the sake of brevity, we show how RLC claim aggregation works for structured layers. For more detail, we highly recommend reading our documentation page!
Recall our example for a structured layer’s sumcheck equation:
If we have the set of claims:
then we have sumcheck equations:
Instead of engaging in sumchecks, however, we take the random linear combination of each of the claims. In other words, let the random coefficients be . Then, we compute the claim , and perform sumcheck over the single equation:
Here, the added cost comes from the larger sumcheck equation. In Remainder, we have several optimizations that take advantage of the structure of the MLE. RLC claim aggregation is often the more performant choice of claim aggregation; however, due to the structure of some layers, such as matmult layers, interpolative claim aggregation may be necessary. Therefore, we offer the option to choose which claim aggregation method to use!
Circuitization Frontend
Finally, we offer an extremely accessible interface to build circuits yourself in Remainder. We highly recommend checking out our quickstart if you would like to get started right away! It offers a step-by-step guide to building your own circuit and running the proving/verifying process within Remainder.
Additionally, if you would like to learn more about the theory and the math behind what goes into Remainder, we wrote a comprehensive overview in our Remainder Book, along with extra resources that helped us understand GKR and Hyrax!
Conclusion
If you made it down here, thanks so much for reading this blog post, and we hope you enjoyed it! We are always looking for suggestions, ideas for features, and feedback on Remainder, so please check out our codebase.
If you're interested in working on problems related to privacy-preserving proof-of-humanity, we're always looking for excited people to join Tools for Humanity—check out our careers page here.
Catch you next time!
Ryan Cao, Vishruti Ganesh, and the Tools for Humanity Applied Research Team
References
- Justin Thaler. (2013). Time-Optimal Interactive Proofs for Circuit Evaluation.
- Justin Thaler. (2013). Proofs, Arguments, and Zero-Knowledge.
- Modulus Labs. (2024). Scaling Intelligence: Verifiable Decision Forest Inference with Remainder.
- Riad S. Wahby, Ioanna Tzialla, abhi shelat, Justin Thaler, & Michael Walfish. (2017). Doubly-efficient zkSNARKs without trusted setup.
- Riad S. Wahby, Ye Ji, Andrew J. Blumberg, abhi shelat, Justin Thaler, Michael Walfish, & Thomas Wies. (2017). Full accounting for verifiable outsourcing.
- Tiancheng Xie, Jiaheng Zhang, Yupeng Zhang, Charalampos Papamanthou, & Dawn Song. (2019). Libra: Succinct Zero-Knowledge Proofs with Optimal Prover Computation.